Edge
The following are common scenarios that you may encounter when using Edge.
Scenario - IP Address not Assigned to Edge Host
When you add a new VMware vSphere Edge host to an Edge cluster, the IP address may fail to be assigned to the Edge host after a reboot.
Debug Steps
-
Access the Edge host through the vSphere Web Console.
-
Issue the following command.
networkctl reloadThis command restarts the Edge host network and allows the Edge host to receive an IP address.
Scenario - Override or Reconfigure Read-only File System Stage
If you need to override or reconfigure the read-only file system, you can do so using the following steps.
Debug Steps
-
Power on the Edge host.
-
Press the keyboard key
Eafter highlighting the menu ingrubmenu. -
Type
rd.cos.debugrwand pressEnter.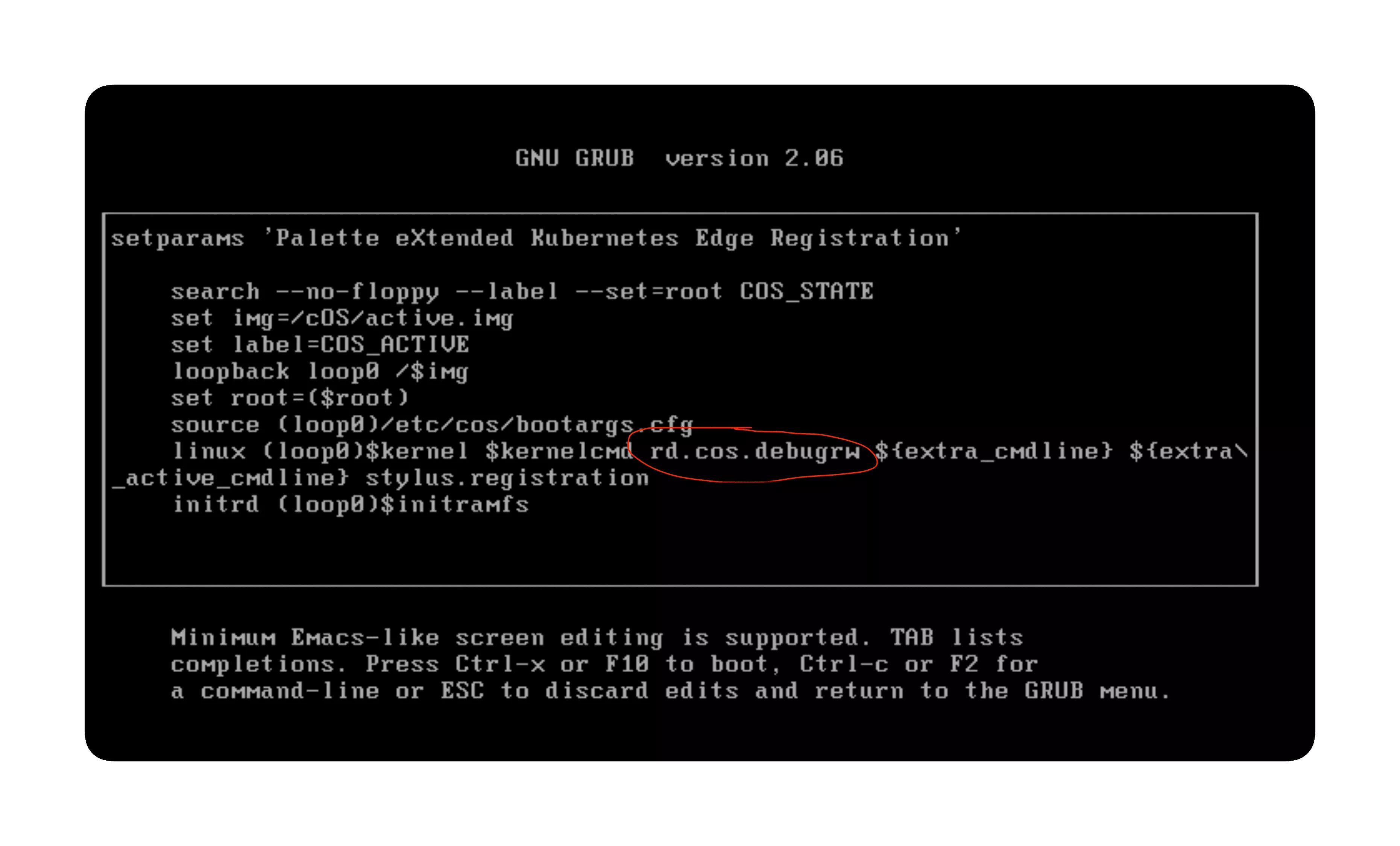
-
Press the keys Ctrl + X to boot the system.
-
Make the required changes to the image.
-
Reboot the system to resume the default read-only file system.
Scenario - Pod State Unknown After Reboot with Overlay Network Enabled
On slower networks, it's possible that this is due to KubeVip leader election timeouts. To debug, you can manually adjust the values of related environment variables in the KubeVip DaemonSet with the following steps.
Debug Steps
-
Ensure you can access the cluster using kubectl. For more information, refer to Access Cluster with CLI.
-
Issue the following command:
kubectl edit ds kube-vip-ds --namespace kube-system -
In the
envof the KubeVip service, modify the environment variables to have the following corresponding values.env:
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "30"
- name: vip_renewdeadline
value: "20"
- name: vip_retryperiod
value: "4" -
Within a minute, the old Pods in unknown state will be terminated and Pods will come up with the updated values.
Scenario - Palette Webhook Pods Fail to Start
If the Palette webhook pods fail to start, it may be due to the palette-lite-controller-manager pods encountering issues or not being available. Use the following steps to troubleshoot and resolve the issue.
Debug Steps
-
Ensure you can access the Kubenetes cluster using kubectl. For more information, refer to Access Cluster with CLI.
-
Open up a terminal session and issue the following command to check the status of the palette-lite-controller-manager pods.
kubectl get pods --all-namespaces | grep palette-lite-controller-managercluster-661acf1dfc746f8217de2712 palette-lite-controller-manager-6856746c8-7p9k2 2/2 Running 0 6mIf the pods are active and available with an age greater than five minutes, then the issue may be with the Palette webhook. Proceed to the next step.
infoIf the pods are not active, use the command
kubectl describe pod <pod-name> --namespace palette-systemto check the pod logs for more information about why the pods are not starting. Replace<pod-name>with the name of the pod that is not starting. Scroll down to theEventssection to view the logs. You can try to delete the pod and check if it starts successfully. If the issue persists, contact our support team by emailing. -
Check the status of the Palette webhook pods. Use the following command to verify the status.
kubectl get pods --namespace palette-systemNo resources found in palette-system namespaceIf the output displays a message stating No resources found in palette-system namespace then the lacking Palette webhook pods are the issue for the cluster not starting.
-
Delete all existing palette-lite-controller-manager pods using the following commands.
export NAMESPACE=$(kubectl get pods --all-namespaces | grep palette-lite-controller-manager | awk '{print $1}')
export PALETTE_POD_NAME=$(kubectl get pods --all-namespaces | grep palette-lite-controller-manager | awk '{print $2}')
kubectl delete pod $PALETTE_POD_NAME --namespace $NAMESPACE -
After a few seconds, verify that the palette-lite-controller-manager pods are active and available.
kubectl get pods --all-namespaces | grep palette-lite-controller-manager -
Check the status of the Palette webhook pods. A successful output should display the status of the palette-webhook pods.
kubectl get pods --namespace palette-systemNAME READY STATUS RESTARTS AGE
palette-webhook-548c55568c-p74zz 1/1 Running 0 2m -
If you continue to encounter issues, contact our support team by emailing support@spectrocloud.com so that we can provide you with further guidance.
Scenario - systemd-resolved.service Enters Failed State
When you create a cluster with an Edge host that operates the Red Hat Enterprise Linux (RHEL) and Ubuntu Operating
Systems (OS), you may encounter an error where the systemd-resolved.service process enters the failed state. This
prevents the nameserver from being configured, which will result in cluster deployment failure.
Debug Steps
-
Establish an SSH connection to the Edge host.
Alternatively, press the keys Fn + Ctrl +Cmd + F1 on a keyboard that is connected to the Edge host to log in to the terminal. If you are on Windows, press Fn + Ctrl + Alt + F1.
-
Issue the following command.
chmod a+rwxt /var/tmp
systemctl enable --now systemd-resolved.serviceThis will start the
systemd-resolved.serviceprocess and move the cluster creation process forward.
Scenario - Degreated Performance on Disk Drives
If you are experiencing degraded performance on disk drives, such as Solid-State Drive or Nonvolatile Memory Express drives, and you have Trusted Boot enabled. The degraded performance may be caused by TRIM operations not being enabled on the drives. TRIM allows the OS to notify the drive which data blocks are no longer in use and can be erased internally. To enable TRIM operations, use the following steps.
Debug Steps
-
Log in to Palette.
-
Navigate to the left Main Menu and click on Profiles.
-
Select the Cluster Profile that you want to use for your Edge cluster.
-
Click on the BYOOS layer to access its YAML configuration.
-
Add the following configuration to the YAML to enable TRIM operations on encrypted partitions.
stages:
boot.after:
- name: Ensure encrypted partitions can be trimmed
commands:
- |
DEVICES=$(lsblk -p -n -l -o NAME)
if cat /proc/cmdline | grep rd.immucore.uki; then TRUSTED_BOOT="true"; fi
for part in $DEVICES
do
if cryptsetup isLuks $part; then
echo "Detected encrypted partition $part, ensuring TRIM is enabled..."
if ! cryptsetup status ${part#/dev/} | grep discards; then
echo "TRIM is not enabled on $part, enabling TRIM..."
if [ "$TRUSTED_BOOT" = "true" ]; then
cryptsetup refresh --allow-discards --persistent ${part#/dev/}
else
if cryptsetup status ${part#/dev/} | grep LUKS2; then OPTIONS="--persistent"; fi
passphrase=$(echo '{ "data": "{ \"label\": \"LABEL\" }"}' | /system/discovery/kcrypt-discovery-challenger "discovery.password" | jq -r '.data')
echo $passphrase | cryptsetup refresh --allow-discards $OPTIONS ${part#/dev/}
fi
if [ "$?" = "0" ]; then
echo "TRIM is now enabled on $part"
else
echo "TRIM coud not be enabled on $part!"
fi
else
echo "TRIM is already enabled on $part, nothing to do."
fi
fi
done -
Click on Confirm Updates to save the changes.
-
Use the updated profile to create a new Edge cluster or update an existing Edge cluster.
Scenario - Clusters with Cilium and RKE2 Experiences Kubernetes Upgrade Failure
When you upgrade your cluster from RKE2 1.29 to 1.30 and your cluster uses the Cilium CNI, the upgrade could fail with error messages similar to the following. This is due to an upstream issue. You can fix this issue by adding a few annotations to the Cilium DaemonSet.
Debug Steps
-
Connect to your cluster using kubectl. For more information, refer to Access Cluster with kubectl.
-
Issue the following command from the terminal edit the Cilium DaemonSet.
kubectl edit ds cilium --namespace kube-system -
Under
metadata.annotations, add the following annotations.metadata:
annotations:
deprecated.daemonset.template.generation: "1"
meta.helm.sh/release-name: cilium-cilium
meta.helm.sh/release-namespace: kube-system
container.apparmor.security.beta.kubernetes.io/cilium-agent: "unconfined"
container.apparmor.security.beta.kubernetes.io/clean-cilium-state: "unconfined"
container.apparmor.security.beta.kubernetes.io/mount-cgroup: "unconfined"
container.apparmor.security.beta.kubernetes.io/apply-sysctl-overwrites: "unconfined"