Two-Node Architecture
Palette Edge allows you to provision a highly available (HA) cluster capable of withstanding any single node failure with only two nodes instead of three. In two-node HA clusters, Palette overcomes a significant limitation of etcd by utilizing Postgres as the backend storage with Kine. Kine is only used in two-node clusters.
Architecture Overview
In a typical Kubernetes cluster, a cluster achieves high availability through the backend key-value store etcd. When a single node goes down, etcd is able to maintain data consistency since its two remaining nodes can still maintain quorum. However, this setup requires at least three nodes. A two-node etcd cluster will not be able to withstand the failure of a node because even the failure of one node will cause the cluster to lose quorum.
In our two-node HA architecture, instead of etcd, we use a Postgres database as the backend storage and a etcd shim named Kine that allows the Kubernetes API to communicate with it as if it is an etcd server. One node is the leader and the other node is the follower. The leader will process write requests and replicate the changes to the follower node. Each node has a liveness probe that periodically probes the other node. When a node goes down, the other node's liveness probe will stop receiving responses and the surviving node will remain the leader or be promoted to become the leader.
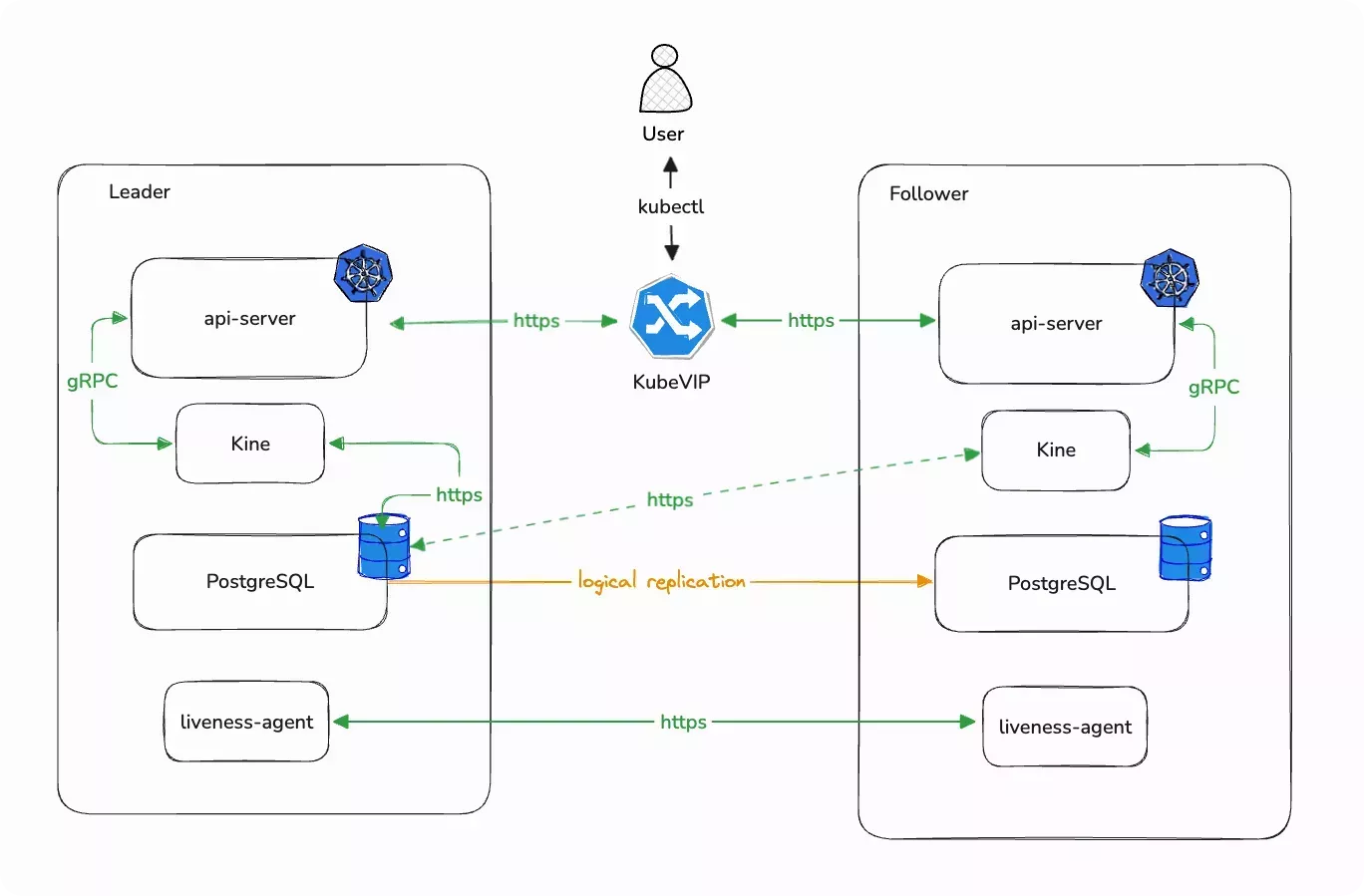
To create two-node Edge clusters, ensure you set the TWO_NODE argument to true during EdgeForge when building
provider images, and toggle on Two-Node Mode during Edge cluster creation. For more information, refer to
Build Provider Images and
Create Cluster Definition. If you create a two-node cluster, you must use
exactly two nodes in the control plane. You will also not be able to change it to a regular etcd-backed cluster or
change the number of nodes.
Limitations
- Two-node clusters can only be deployed in central management mode. You cannot deploy hosts in local management mode.
- Agent mode is not supported for two-node clusters because two-node high availability relies on Kairos, which is only used in appliance mode. For more information, refer to Deployment Modes.
- Two-node clusters can only have exactly two nodes in the control plane pool. You cannot adjust the number of the nodes in the control plane pool after cluster creation.
- Two-node clusters only support K3s and Palette Optimized Canonical Kubernetes. Other Kubernetes distributions are not supported.
Use Cases
The two-node architecture prioritizes availability, but does make a slight sacrifice in data consistency in a split-brain scenario. This architecture is most suitable in situations where the priority for availability is high, the risk for network split is low, and a slight loss during a network split event is acceptable when compared with total availability loss. When these conditions are met, adopting the two-node architecture allows you to save 33% of costs on hardware alone, with further savings on cable management, operations, space, and transportation.
Example use cases include the following:
- Point-of-sale systems stationed in Edge locations such as retail stores, restaurants, and coffee shops.
- Industrial Internet of Things (IIoT) gateways at factories and industrial sites.
- Automated inventory systems in retail and distribution warehouses.
Leader Promotion After Node Failure
When the leader node of a two-node cluster fails, the liveness probe on the follower node will stop returning healthy results. Once there are enough unhealthy responses, the follower node will initiate the promotion process to promote itself as the leader. During this time, the different Kubernetes components become temporarily unavailable. The liveness probe would make adjustments to the instance of Kine on the node so that its requests are now directed to the new leader node's own instance of Postgres. The probe also performs a few SQL commands on the Postgres table to make sure that it is ready for when the cluster comes back online.
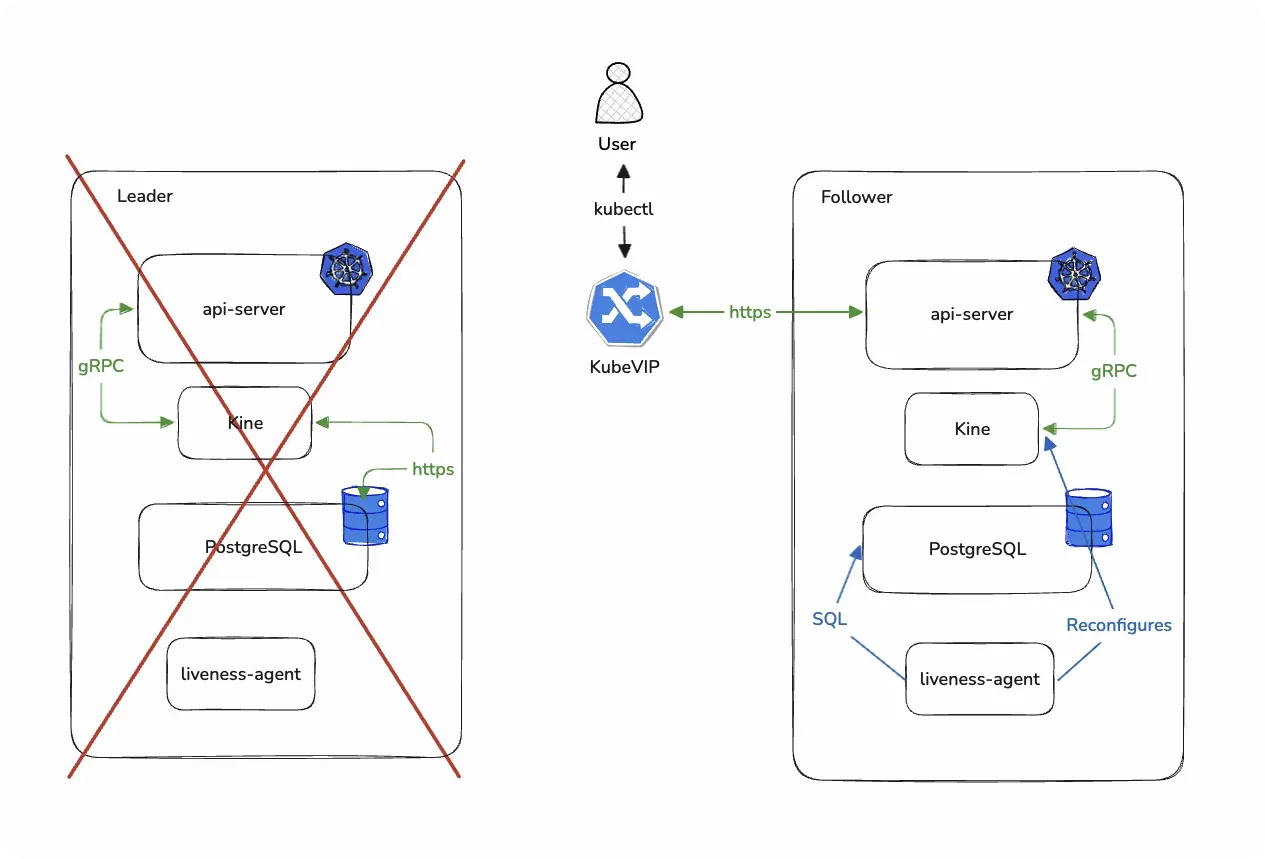
Once all adjustments have been made, the Kubernetes cluster will come back online and start processing requests.
Restore High Availability
When you re-introduce another node to your now one-node cluster to restore high availability, the cluster behavior is different depending on the timestamp of the most recent state changes in the two nodes. The node with the more recently timestamped state change will become the leader
Restore After Failure
If you introduce a node that had previously failed, the previously failed node will drop its database in its entirety and sync with the current leader as a follower, because the node does not have a more recently timestamped state change compared with the current leader node. If you introduce a new node that was never part of the cluster, it will also sync with the current leader and become a follower. No data loss is incurred in this scenario because the dropped dataset is entirely duplicated in the surviving node.
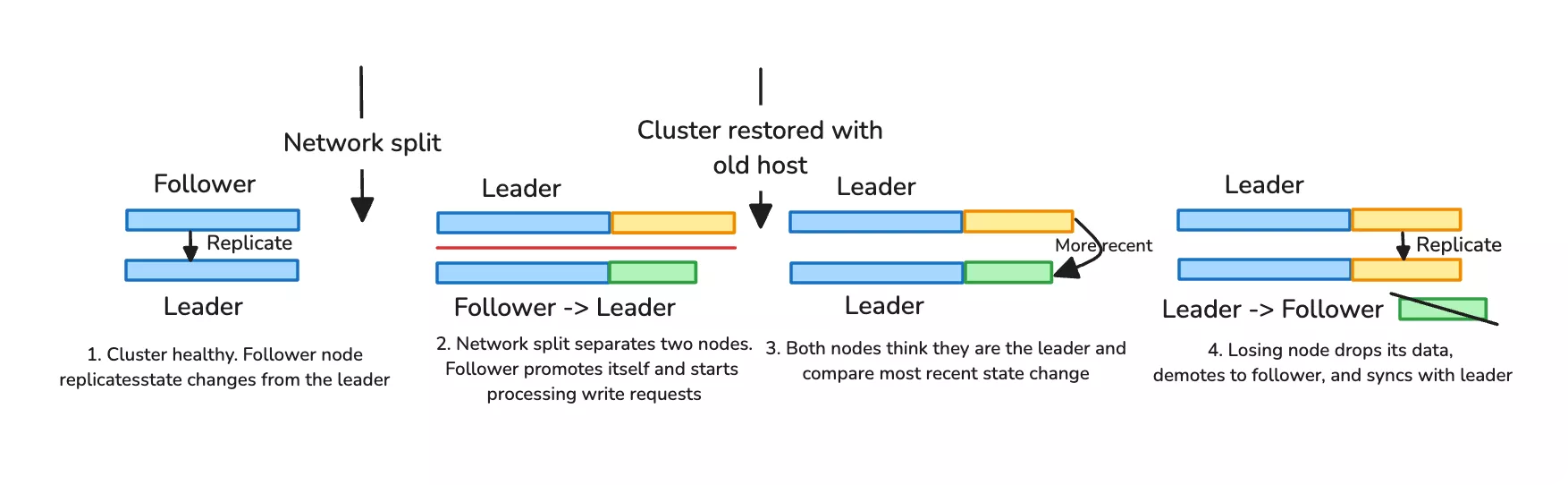
Restore After Network Split and Potential Data Loss
If a network split occurs, both nodes will assume the other node has experienced failure and start operating as the new leader. When you re-introduce both nodes to the same cluster, the nodes will compare the timestamp of their most recent state change. The node with the most recent state change is elected leader, and the losing node will drop its entire database to sync with the leader node as a follower. This may incur a small amount of data loss, as the data written to the losing node during the split is not retained.
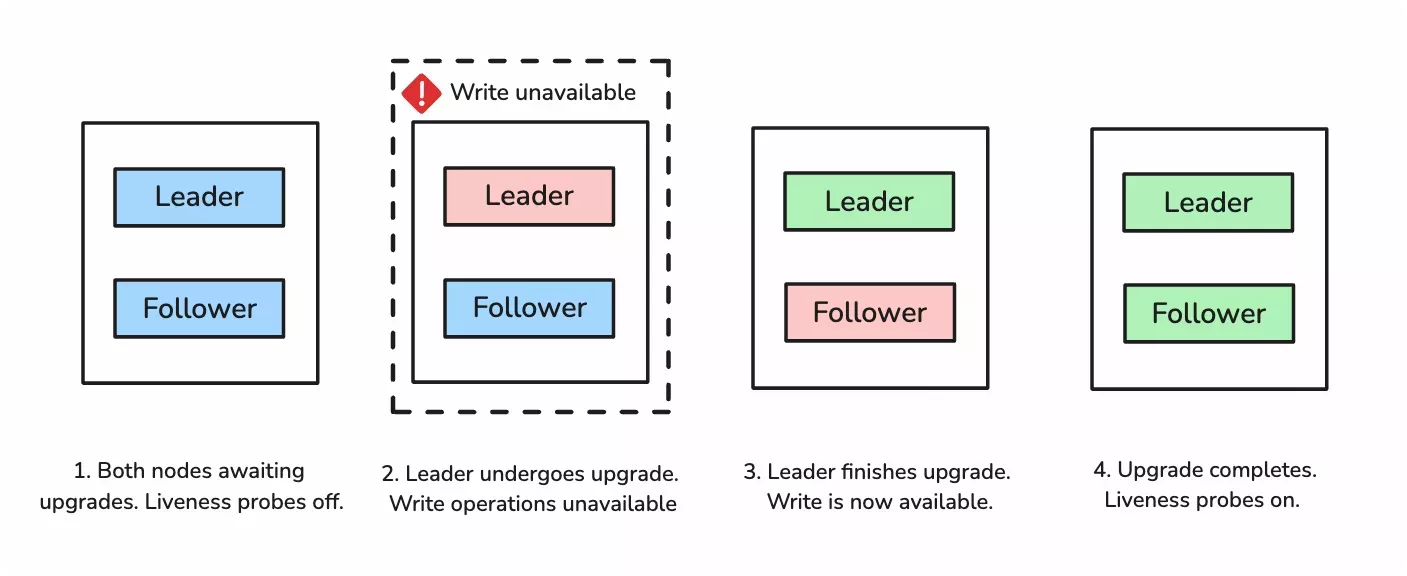
Upgrade Behavior
Upgrading a two-node cluster involves a small amount of downtime for write operations. Upgrading a cluster does not change the role of either node. Both nodes retain their original roles.
During an upgrade, the liveness probes on both nodes are paused to avoid the accidental promotion of the follower node. Then one of the nodes is selected at random to undergo the upgrade first. Once the upgrade is complete, the cluster upgrades the other node. Read requests will continue to be processed because one of the nodes is always available. Write requests will be temporarily unavailable as the leader node goes down during the upgrade. Once both nodes are upgraded, both nodes resume the liveness probes.